Quay Deployment and Configuration using GitOps
-
 Thomas Jungbauer
( Lastmod: 2024-05-08 )
-
4 min read
Thomas Jungbauer
( Lastmod: 2024-05-08 )
-
4 min read
Installing and configuring Quay Enterprise using a GitOps approach is not as easy as it sounds. On the one hand, the operator is deployed easily, on the other hand, the configuration of Quay is quite tough to do in a declarative way and syntax rules must be strictly followed.
In this article, I am trying to explain how I solved this issue by using a Kubernetes Job and a Helm Chart.
What about Quay configuration?
Quay Enterprise is using a (quite big) Secrets object that defines tons of settings for the registry. The syntax must strictly be followed.
For example, a Boolean must be true or false. Quay ignores if a string like "true" or "false" is provided.
This alone is already a hassle since working with Booleans in Helm is not as easy as you might think.
The Secret combines non-sensitive data (like DEFAULT_TAG_EXPIRATION) with sensitive data (like settings for the Object Store)
If there is any error in the configuration file, or if the Operator is configured to manage a specific component, but finds settings for this component in the Secret, the deployment will fail.
The solution?
I thought for a long time about how to solve this issue. One solution might be to create the whole Secret upfront and simply provide it during the deployment. This works and I have done this previously, but I wanted to generate the Secret during the deployment.
Therefore, I am now trying to create a ConfigMap that holds a complete skeleton of the required Secret. This ConfigMap is used by a Kubernetes Job, which reads the required sensitive information out of other existing Secrets (such as S3 information) and generates a quay-secret by replacing the required fields.
Is this the perfect and optimal way to do that? Probably not, however, it works :)
Let us see that in action
Prerequisites
First, we have some prerequisites.
Quay is very … very hungry for resources. Quay application pods require 8 CPU and 16GB Memory per pod and per default… and it tries to spin up 2 pods. The same goes for Clair and so on. Therefore, I will configure Quay to only use 1 replica for these services.
Quay requires node roles
infra. I am not sure if this is new or if I never saw that, but the nodeSelector, which it seems you cannot configure, is looking for the label infra. Therefore, the nodes that should host Quay must have the label:node-role.kubernetes.io/infra: ''Currently, I am using a
BucketClaimobject to create an S3-bucket and once created I read the required information of the bucket to replace the settings in the generated Quay configuration accordingly. The BucketClaim object comes from the OpenShift Data Foundation. I installed the Multicloud Object Gateway only, which allows me to provide Object Storage (S3). (Very useful to test other solutions too, like OpenShift Logging or Network Observability)
Meeting these requirements, allows us to deploy Quay. But first some theory.
Deployment Workflow
The workflow of the deployment is as the following image demonstrates
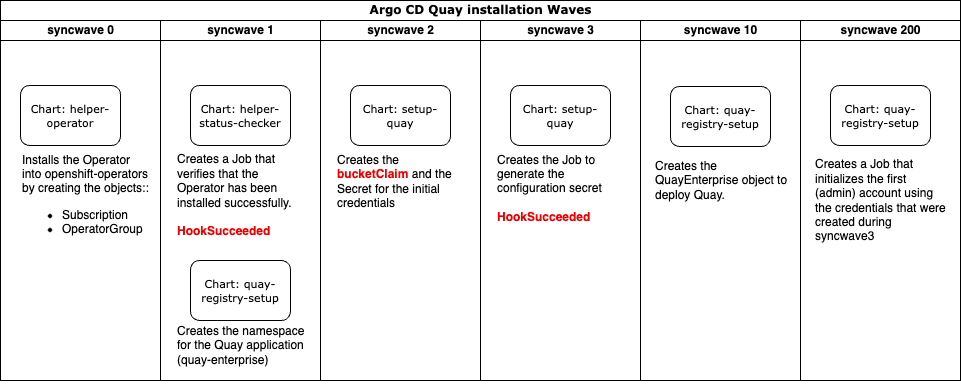
Everything starts with the Helm Chart setup-quay. This Chart itself provides the logic to create an S3-bucket, a Job to generate the configuration and the creation of a Secret, that provides the initial administrator credential.
setup-quay has multiple dependencies to other Helm charts, that can be found at my Helm repository:
Configuration
All values for the Helm Charts can be found in the values file
Since sub-charts are used the file is divided into 4 blocks:
helper-operator: Here the sub-chart helper-operator is configured. All settings here are bypassed to the subchart. It defines the required settings to deploy the operator.
helper-status-checker: Here settings for the status-checker Job are defined.
quay-registry-setup: This defines the actual configuration of the QuayEnterprise object. It will spin up the Quay instance. Some components are set to "false" or "replica == 1" to minimize the required resources in my lab. For a production environment, additional replicas or components might be required.
quay: These are the actual values for the configuration. It defines the bucketClaim as well as settings for the Quay configuration that might be overwritten.
Deploy it
Using for example the following Argo CD Application we can deploy everything.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: in-cluster-setup-quay
namespace: openshift-gitops
spec:
destination:
name: in-cluster (1)
namespace: default
ignoreDifferences: (2)
- jsonPointers:
- /data/password
kind: Secret
name: init-user
namespace: quay-enterprise
info:
- name: Description
value: ApplicationSet that Deploys on Management Cluster (Matrix Generator)
project: in-cluster
source:
path: clusters/management-cluster/setup-quay (3)
repoURL: 'https://github.com/tjungbauer/openshift-clusterconfig-gitops'
targetRevision: main| 1 | The destination cluster. Here the "in-cluster" means the local cluster of Argo CD. |
| 2 | The initial credential for Quay is being generated and would change if the Argo CD application gets refreshed and therefore it would be out of sync. So, we are ignoring differences in the password field. |
| 3 | The source of the Helm Chart. |
In Argo CD this Application will look like
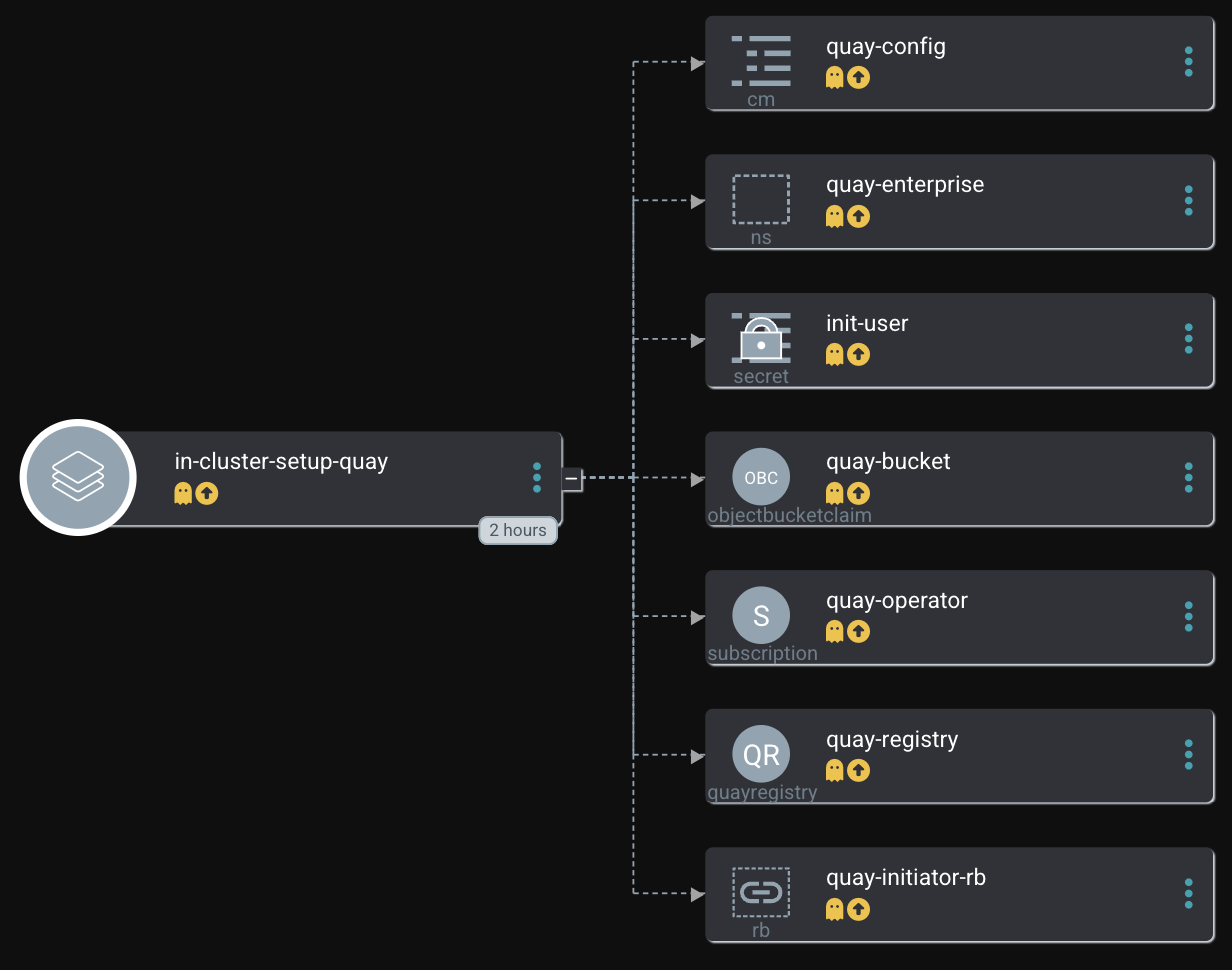
Deployment means in GitOps approach: synchronizing the Argo CD Application.
This will install the Operator and spin up all required Pods and Jobs. It will take several minutes until everything is up and running. During the deployment, some Pods may fail and will get restarted automatically. This happens because they are dependent on the Postgres DB which must be started first.
Quay is Alive
Congratulations, you have now a Quay instance. Use the auto-generated
credentials, that are stored in the Secret init-user to authenticate.
Is that All - Kind of Summary?
Several configurations are done here now. However, there are tons to follow. For example, log forwarding or additional certificates. Some settings will contain sensitive information some will not. All these settings can be added to the ConfigMap skeleton and be replaced accordingly with "little" effort. For me, it is simply not possible to test every setting and possibility. Maybe I will extend the Helm Chart during the journey. If you find this useful, feel free to re-use it and of course, if you find any issues feel free to create a GitHub issue.
Copyright © 2020 - 2024 Toni Schmidbauer & Thomas Jungbauer