[Ep.2] Choosing the right Git repository structure
December 28, 2023
Updated Dec 18, 2025
-
![]() Thomas Jungbauer
-
8 min read
(1508 words)
Thomas Jungbauer
-
8 min read
(1508 words)
One of the most popular questions asked before adopting the GitOps approach is how to deploy an application to different environments (Test, Dev, Production, etc.) in a safe and repeatable way.
Each organisation has different requirements, and the choice will depend on a multitude of factors that also include non-technical aspects.
Therefore, it is important to state: "There is no unique “right” way, there are common practices".
| In this series, I will focus on cluster configuration. |
Git Repository Strategy - Options
As written in the introduction: There is no unique “right” way, there are common practices. But how shall the Git repository structure look like? How shall the folder structure look like? Multiple options might be considered. Each has advantages and disadvantages, some I would recommend, some I would not recommend.
It is important to understand that:
The Git repository structure will depend heavily on how the organisation is laid out.
The final repo and directory structure is unique for every organisation, as such the right one will be a discovery process within the organisation and the teams involved in the GitOps engineering process.
Before I describe what I usually try to leverage, let’s see the different options.
Environment-per-branch
In this case, there is a Git branch for each environment. A “Dev” branch holds the configuration for the DEV environments, a “production” branch for production and so on. This approach is very popular and will be familiar to people who have adopted git flow in the past. However, it is focused on application source code and not environment configuration and is best used when you need to support multiple versions of your application in production. I do not recommend this approach for GitOps, the main reasons are that pull requests and merges will be very complex and promotions between environments are a hurdle. The whole life cycle of a cluster configuration will be very complex.
Environment-per-folder - Monorepo
In this case, all environments are in a single Git repository, and all are in the same branch. The filesystem has different folders that hold configuration files for each environment. The configuration of the “DEV” environment is described by a “DEV” folder, the “production” environment is found in a “production” folder and so on.
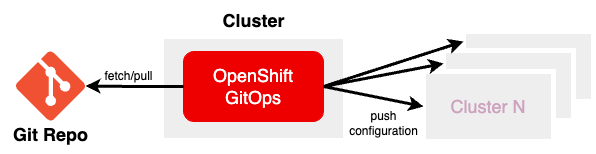
This is the approach I usually recommend, especially when someone is new to the whole GitOps workflow and because of the simplicity of setting up such a repository.
The following advantages and disadvantages should be considered:
Pros
Provides a central location for configuration changes.
This simplicity enabled straightforward Git workflows that will be centrally visible to the entire organisation, allowing a smoother and clearer approval process and merging.
Better suitable for small teams that are managing the cluster and easy to read and understand
Easy to debug problems.
Cons
Scalability >> Increase complexity >> Management
Performance for huge repositories
Challenging to control access permissions on a single repository
Environment-per-repository - Multirepo
In this case, each environment is on its separate git repository. So, the DEV environment is in a git repository called “DEV”, the “production” environment is in a “production” git repository and so on. The GitOps agent (OpenShift GitOps) connects to multiple repositories and takes care to apply the correct configuration to the correct target cluster.
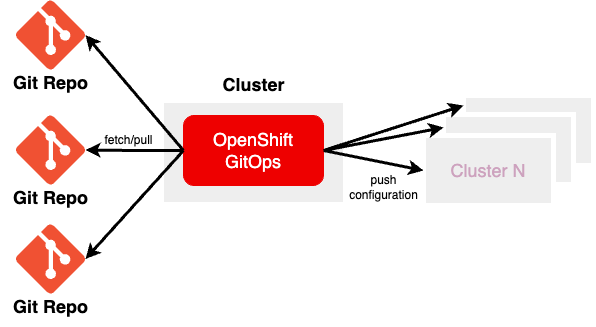
Like the Monorepo approach, Multirepo comes with some advantages and disadvantages:
Pros
Allows separating concerns between different departments of organisations (a repository for the security team, a repository for the operations team, etc.)
Cons
More complex to manage
Harder to understand and read the configuration (what is coming from where)
Argo CD Application dependencies might not be solved (i.e., Security tries to manage the same object as the operating team. Who is the leader?)
Example Setup
The Approach I choose
I usually use and recommend Monorepo approach. The environment-per-folder approach is a very good way to organise your GitOps applications. Not only is it very simple to implement and maintain, but it is also the optimal method for promoting releases between different GitOps environments. This approach can also work for any number of environments without any additional effort. Cluster configurations (for multiple clusters) are typically done by one team, therefore controlling access permissions in Git is not a big issue.
Example Folder Structure
Over time the following folder structure evolved or my repository:
├── base (1)
│ ├── argocd-resources-manager (2)
│ └── init_app_of_apps (3)
├── charts (4)
├── clusters (5)
│ ├── all (6)
│ │ ├── base-operators
│ │ ├── etcd-encryption
│ ├── management-cluster (7)
│ │ ├── branding
│ │ ├── generic-cluster-config
│ │ ├── management-gitops
│ │ ├── node-labels
│ │ ├── openshift-data-foundation
│ │ ├── setup-acm
│ │ ├── setup-acs
│ │ ├── setup-compliance-oeprator
│ │ ├── setup-openshift-logging
│ │ └── setup-quay
│ └── production-cluster (8)
│ │ ├── branding
│ │ ├── generic-cluster-config
│ │ ├── node-labels
│ │ ├── openshift-data-foundation
│ │ ├── setup-acs
│ │ ├── setup-compliance-oeprator
│ │ └── setup-openshift-logging
├── init_GitOps.sh (9)
├── scripts (10)
│ ├── example_htpasswd
│ ├── sealed_secrets
├── tenant-projects (11)
├── my-main-app
└── my-second-app| 1 | The base folder contains basic configurations or Argo CD itself. |
| 2 | The argocd-resources-manager is a Helm Chart that configures Applications and ApplicationSets or Argo CD using a single configuration file. |
| 3 | The init_app_of_apps is used during the initial installation of OpenShift GitOps and installs the App-of-Apps that manages other Applications or Argo CD. This Application automatically synchronises and watches for changes in the folder argocd-resources-manager. |
| 4 | The charts folder is optional and can store local Helm Charts. Usually, it is better to release the Charts in a Helm repository, where they can be managed independently to the cluster configuration repository. |
| 5 | The folder for the different clusters. |
| 6 | Configurations that are equal for all clusters and simple to achieve without any deeper configuration. Currently, for example, the activation of the etcd encryption and the deployment of base Operators that every cluster will require. In this case, the Operators are installed only, without further configuration. |
| 7 | Configuration for the management-cluster. For example, deploying ACM, ACS, Quay or any generic cluster configuration. Here we see immediately what is deployed and where I can modify the configuration for that cluster. |
| 8 | Configuration for the production-clusters |
| 9 | The deployment script to install and configure the OpenShift GitOps Operator. This might be replaced or at least modified in the future once PlatformOperators are generally available and not in a technology preview state anymore. |
| 10 | The scripts folder simply contains some shell scripts that might be useful. For example, to backup a Sealed Secrets key or generate a htpasswd file. |
| 11 | The tenant-projects folder is a special folder to store the configuration or projects. Any project onboarding is configured here, such as Quota, LimitRanges, NetworkPolicies etc. |
Why the repeating folders?
Some may argue why certain folders are equal for management and production clusters, for example, "setup-compliance-operator", when this could be done more easily by defining such folder only once and using different overlays (using Kustomize) or different values-files (using Helm Charts). However, while this is a very valid question, I personally, like to see immediately what is configured on each cluster. I see, based on the folders, what is configured on the management cluster and where I could modify the configuration.
Using Kustomize overlays, for example, would mean recreating the overlays for each configuration (if you want to have a clean separation and not combine all manifests into one overlay). Using different values-files is again a valid option, but (also again), you do not see what is configured on which cluster with one look.
Therefore, I like this folder structure, even if it may look weird (especially if you are used to Kustomize overlays). However, everyone is invited to define their very own structure :)
Managing Kubernetes Manifests
The Kubernetes manifests (the yaml files) must be managed in a way Argo CD can read and synchronise them.
Three main options are commonly used:
Helm: Helm uses a packaging format called charts. A chart is a collection of files that describe a related set of Kubernetes resources.
Kustomize: A Template-free way to customise application configuration that simplifies the use of off-the-shelf applications.
Plain Text: Plain text Kubernetes objects provided in YAML of JSON format.
| Argo CD also understands jsonnet or even custom plugins. However, I had no customer up until now, who wanted to use something else than Kustomize or Helm. |
The different tools are not explained in detail in this article, but the choice of the tool highly depends on the existing knowledge and individual preferences inside the company. Every option has advantages and disadvantages that will become visible when they are used.
I have seen companies tend to use Helm Charts or Plain Text, especially when they are new to the tools. However, no tool is better than the other. Instead, the tools can be combined which might be useful for some use cases.
| Kustomize and Helm do not exclude each other and can be combined. However, for the start, a single tool should be selected. |
Related Articles
Copyright © 2020 - 2026 Toni Schmidbauer & Thomas Jungbauer
Discussion
Comments are powered by GitHub Discussions. To participate, you'll need a GitHub account.
By loading comments, you agree to GitHub's Privacy Policy. Your data is processed by GitHub, not by this website.