Node Affinity allows to place a pod to a specific group of nodes. For example, it is possible to run a pod only on nodes with a specific CPU or disktype. The disktype was used as an example for the nodeSelector and yes … Node Affinity is conceptually similar to nodeSelector but allows a more granular configuration.
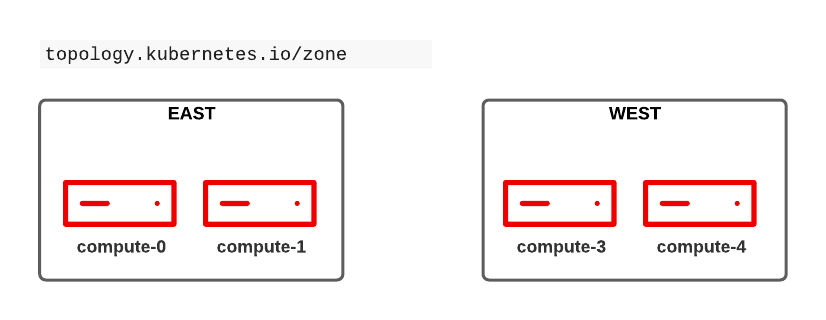
In this example the pods are started only on nodes of the zone "West". Since the value is an array, multiple zones can be defined letting the web application be executed on West and East for example.
With this setup you can control on which node a specific application shall be executed. For example: you have a group of nodes which provide a GPU and your GPU application must be started only on this group of nodes.
Like with pod affinity you can combine required and preferred settings.
What happened to Node Anti-Affinity?
Unlike Pod Anti-Affinity, there is no concept to define a node Anti-Affinity. Instead you can use the NotIn and DoesNotExist operators to achieve this bahaviour.
Cleanup
As cleanup simply remove the affinity specification from the DeploymentConf. The node labels can stay as they are since they do not hurt.
Summary
This concludes the quick overview of the node affinity. Further information can be found at Node Affinity
One of the most commonly deployed operators in OpenShift environments is the Cert-Manager Operator. It automates the management of TLS certificates for applications running within the cluster, including their issuance and renewal.
The tool supports a variety of certificate issuers by default, including ACME, Vault, and self-signed certificates. Whenever a certificate is needed, Cert-Manager will automatically create a CertificateRequest resource that contains the details of the certificate. This resource is then processed by the appropriate issuer to generate the actual TLS certificate. The approval process in this case is usually fully automated, meaning that the certificate is issued without any manual intervention.
But what if you want to have more control? What if certificate issuance must follow strict organizational policies, such as requiring a specifc country code or organization name? This is where the CertificateRequestPolicy resource, a resource provided by the Approver Policy, comes into play.
This article walks through configuring the Cert-Manager Approver Policy in OpenShift to enforce granular policies on certificate requests.
The following 1-minute article is a follow-up to my previous article about how to use Keycloak as an authentication provider for OpenShift. In this article, I will show you how to configure Keycloak and OpenShift for Single Log Out (SLO). This means that when you log out from Keycloak, you will also be logged out from OpenShift automatically. This requires some additional configuration in Keycloak and OpenShift, but it is not too complicated.
I was recently asked about how to use Keycloak as an authentication provider for OpenShift. How to install Keycloak using the Operator and how to configure Keycloak and OpenShift so that users can log in to OpenShift using OpenID. I have to admit that the exact steps are not easy to find, so I decided to write a blog post about it, describing each step in detail. This time I will not use GitOps, but the OpenShift and Keycloak Web Console to show the steps, because before we put it into GitOps, we need to understand what is actually happening.
This article tries to explain every step required so that a user can authenticate to OpenShift using Keycloak as an Identity Provider (IDP) and that Groups from Keycloak are imported into OpenShift. This article does not cover a production grade installation of Keycloak, but only a test installation, so you can see how it works. For production, you might want to consider a proper database (maybe external, but at least with a backup), high availability, etc.).
During my day-to-day business, I am discussing the following setup with many customers: Configure App-of-Apps. Here I try to explain how I use an ApplicationSet that watches over a folder in Git and automatically adds a new Argo CD Application whenever a new folder is found. This works great, but there is a catch: The ApplicationSet uses the same Namespace default for all Applications. This is not always desired, especially when you have different teams working on different Applications.
Recently I was asked by the customer if this can be fixed and if it is possible to define different Namespaces for each Application. The answer is yes, and I would like to show you how to do this.
Classic Kubernetes/OpenShift offer a feature called NetworkPolicy that allows users to control the traffic to and from their assigned Namespace. NetworkPolicies are designed to give project owners or tenants the ability to protect their own namespace. Sometimes, however, I worked with customers where the cluster administrators or a dedicated (network) team need to enforce these policies.
Since the NetworkPolicy API is namespace-scoped, it is not possible to enforce policies across namespaces. The only solution was to create custom (project) admin and edit roles, and remove the ability of creating, modifying or deleting NetworkPolicy objects. Technically, this is possible and easily done. But shifts the whole network security to cluster administrators.
Luckily, this is where AdminNetworkPolicy (ANP) and BaselineAdminNetworkPolicy (BANP) comes into play.
 Thomas Jungbauer
( Lastmod: 2024-05-08 )
-
2 min read
Thomas Jungbauer
( Lastmod: 2024-05-08 )
-
2 min read