Node Affinity
August 26, 2021
(Rev: 2025-12-02)
-
 Thomas Jungbauer
-
2 min read
(436 words)
Thomas Jungbauer
-
2 min read
(436 words)
Node Affinity allows to place a pod to a specific group of nodes. For example, it is possible to run a pod only on nodes with a specific CPU or disktype. The disktype was used as an example for the nodeSelector and yes … Node Affinity is conceptually similar to nodeSelector but allows a more granular configuration.
Pod Placement Series
Please check out other ways of pod placements:
Using Node Affinity
Currently two types of affinity settings are known:
requiredDuringSchedulingIgnoreDuringExecuption (short required) - a hard requirement which must be met before a pod can be scheduled
preferredDuringSchedulingIgnoredDuringExecution (short preferred) - a soft requirement the scheduler tries to meet, but does not guarantee it
| Both types can be specified. In such case the node must first meet the required rule and then attempt to meet the preferred rule. |
Preparing node labels
| Remember the prerequisites explained in the . Pod Placement - Introduction. We have 4 compute nodes and an example web application up and running. |
Before we start with affinity rules we need to label all nodes. Let’s create 2 zones (east and west) for our compute nodes.
| You can skip this, if these labels are still set. |
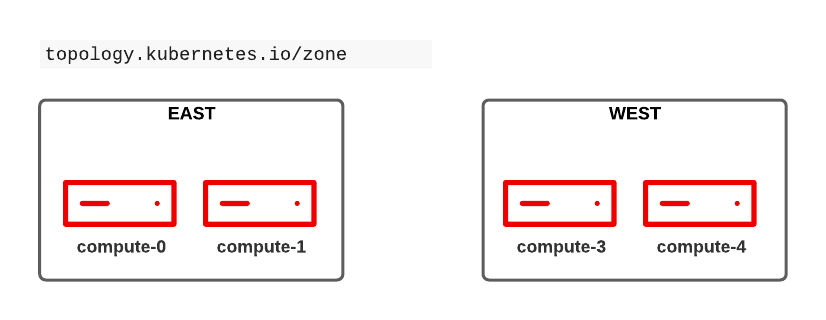
oc label nodes compute-0 compute-1 topology.kubernetes.io/zone=east
oc label nodes compute-2 compute-3 topology.kubernetes.io/zone=westConfigure node affinity rule
Like pod affinity the node affinity is defined on the pod specification:
kind: DeploymentConfig
apiVersion: apps.openshift.io/v1
metadata:
name: django-psql-example
namespace: podtesting
[...]
spec:
[...]
template:
[...]
spec:
[...]
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- westIn this example the pods are started only on nodes of the zone "West". Since the value is an array, multiple zones can be defined letting the web application be executed on West and East for example. With this setup you can control on which node a specific application shall be executed. For example: you have a group of nodes which provide a GPU and your GPU application must be started only on this group of nodes.
Like with pod affinity you can combine required and preferred settings.
What happened to Node Anti-Affinity?
Unlike Pod Anti-Affinity, there is no concept to define a node Anti-Affinity. Instead you can use the NotIn and DoesNotExist operators to achieve this bahaviour.
Cleanup
As cleanup simply remove the affinity specification from the DeploymentConf. The node labels can stay as they are since they do not hurt.
Summary
This concludes the quick overview of the node affinity. Further information can be found at Node Affinity
Copyright © 2020 - 2025 Toni Schmidbauer & Thomas Jungbauer
Discussion
Comments are powered by GitHub Discussions. To participate, you'll need a GitHub account.
By loading comments, you agree to GitHub's Privacy Policy. Your data is processed by GitHub, not by this website.